Before AI, there was good data
An often under-appreciated fact: when it comes to AI, not all data is equally amenable to applications of ML. In this post, we cover what this means and what to look out for. We also briefly touch on some aspects of the problem that we tackle for biotechs with Kaleidoscope. As always, if anything here resonates, please reach out!
Summary points
- Applying ML begins with being thoughtful about data. Understanding things like what data you're generating, how you're generating it, and why you're doing so, are some key fundamentals to answer first.
- For a successful AI motion, many things have to happen below the surface. Defining, collecting, storing, and cleaning data are just some examples of what underpins the actual learning/optimization part of applying ML to your data.
- Kaleidoscope can help with some of these aspects, particularly when it comes to collating, labeling, and managing collaborative data flows, and connecting these to the why: your critical R&D decisions and milestones.
A couple of months ago in this post on defensive moats, we touched on how quickly AI is developing. R&D scientists across the board are eager to incorporate AI and machine-learning models into their work, and these models are poised to change the way we discover drugs. There’s a whole new generation of AI initiatives that are focused on common failure points in the drug development pipeline – like picking the right target in the body, designing the right molecule to interact with it, determining which patients that molecule is most likely to help.
It’s an exciting time, and while there’s been no shortage of people in the bio world writing about all the different ways AI can speed up R&D, there is a shortage of people writing about the step that has to come before the models: data preparation and quality.
When it comes to ML models, you are what you eat. This is the garbage in, garbage out idea that bad data leads to bad results, algorithms, and ultimately outcomes. For example, if a diagnosis model is trained only on data from adults, you wouldn’t trust it to accurately diagnose children, who can exhibit different symptoms or show different image patterns for the same diseases. Ultimately, bad data can break or make a model’s predictive ability.
The reality is, most bio companies today are not ready to apply ML models to their work because they haven’t solved the ‘garbage in’ side of the equation. Beyond the examples above, ‘garbage’ can look like a lot of different things: data that is incorrectly entered, mislabeled, incomplete, biased, inconsistent, duplicated, unstructured, and more.
One of the reasons data quality has had less emphasis than it deserves, in this new wave of AI discourse, is the supreme focus on data as a commodity. The metaphor of oil for data is incredibly pervasive, down to even the core vocabulary we use: data extraction, data mining, data pipeline – making it easy to get caught up in the idea of quantity over quality. After all, when it comes to oil, more is more.
But data is not like oil! It’s a lot harder to improve the quality of data by removing impurities from it later on. Rather, this is something you should think about ahead of time. Good quality data is created by ensuring your process for creating the data is robust.
Quality goes beyond just collection, too; the structure of the data you collect is rarely de facto optimized for the predictive model you intend to feed it into. It has to be standardized, cleaned, organized, labeled that way with intentionality. Smaller datasets, when collected in a disciplined, thoughtful manner, can have a lot of signal, and in a future where AI and ML systems will become the norm, focusing on data quality has to be the immediate priority. Vega Shah at Benchling wrote something similar recently: “as un-sexy as it is, companies need to build their data strategy and systems before benefiting from AI and ML.”
But how should companies go about redesigning their data systems so they’re amenable for AI models? Seven years ago, Monica Rogati wrote a great post on Hacker Noon called the AI Hierarchy of Needs. AI and deep learning sit at the top of the pyramid, and the bottom of that pyramid is made up of five steps: collecting, storing, transforming, labeling, and optimizing data.
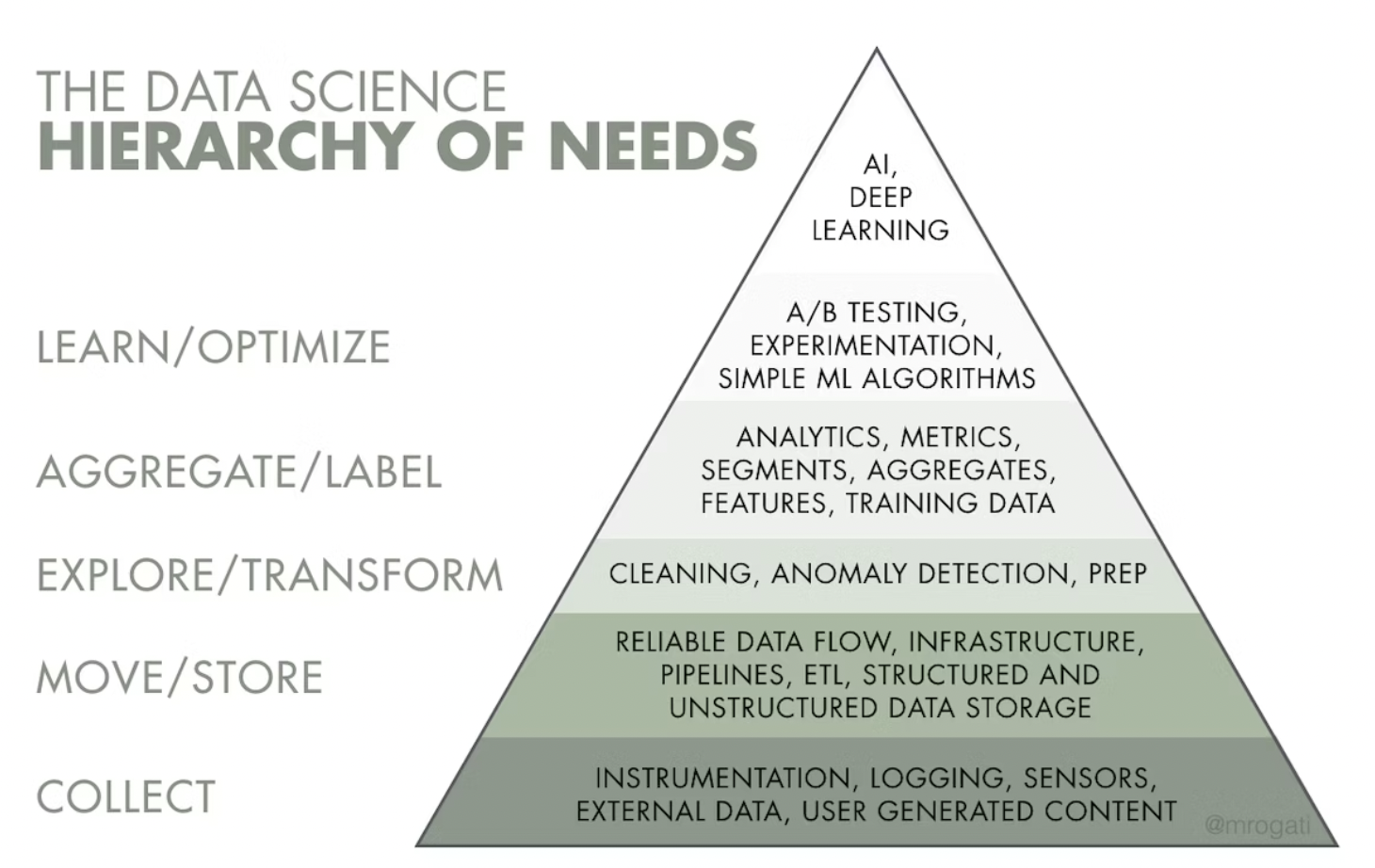
The idea is that reaching the higher tiers of the AI Hierarchy of Needs is much harder when the lower tiers are missing or poorly implemented. Monica’s post is a great roadmap for any company – bio or not – looking to get their data in good shape to start effectively using AI.
Wrangling data into a ‘model ready’ state is rarely any data scientist’s favorite part of the job, and it’s natural to feel intimidated by a task that seems so challenging and time-consuming from the outset. Part of this intimidation stems from the misconception that model datasets have to be perfect in order to be usable. They don’t. The reality is, flawless datasets rarely exist!
Instead of chasing perfect datasets, biotech companies should be in pursuit of something different: useful datasets and best practices that make it possible to leverage their power. This is what we’re helping create at Kaleidoscope, with our suite of features that not only provide utility in the day-to-day, but enable teams to put that data to use down the line.
For instance, when it comes to commissioning and collecting external data, we give teams a flow that lets them request data of a certain type or format, validate upon arrival that it fits those rules, and index it appropriately. Similarly, when it comes to dealing with internal data imports or syncs across tools, Kaleidoscope runs health checks on that data and provides users with an intuitive, guided flow for correcting and cleaning it, directly in the UI, to ensure best practices around hygiene and organization.
We’ve also productized a range of functions for the more middle-of-the-pyramid (exploring and labeling) pieces. For example, we’ve baked in the concept of metadata annotation across the platform, so that our customers can preserve key context at the program, project, or experiment level. Kaleidoscope also gives teams a framework for labeling or tagging key information. In addition to being able to group, segment, and track data in different functional ways using these labels, they also allow for powerful downstream learning of what data led to what decision led to what outcome.
Regardless of the specific framework or process used, the key thing to keep in mind is that being thoughtful about how you work with data today will have a huge impact on your ability to leverage AI tomorrow. At Kaleidoscope, our approach is to give our users clear, near-term functionality (supercharged collaboration and productivity) that provides powerful, compounding, long-term value (truly harnessing their data).
If you want to chat more about anything we wrote, or you’re interested in finding a way to work together, let us know!