Building the platform of the future
When we started building Kaleidoscope, we didn’t set out to build an end-to-end platform.
Our initial observation was much narrower. A growing share of scientific work was happening at the intersection of computational and experimental workflows, and the most important decisions were rarely made within a single team. They emerged across boundaries. Wet lab, dry lab, external partners, internal programs. The problem that we cared about was how to connect those threads in a way that reflected how work actually happened.
As we set out to solve that problem, there was an implicit assumption we formed: that the foundational layers - like lab notes, registries, inventory, and systems of record - already existed. Maybe they weren’t perfect, but they were good enough. And so, we thought, the sensible strategy was to integrate with them rather than set out to replace them. In our minds, compatibility mattered more than completeness.
That assumption held up. Until it didn’t.
As we spent more time with teams, the assumption started to crack. The problems those systems were supposed to solve weren’t actually solved, at least not in the context of how modern R&D operates. In some cases, they had never been solved. In others, they had been solved for a previous version of the problem. The structure of the work had changed, but the tools hadn’t.
That gap shows up in subtle ways at first. A system without an API. Data that technically exists but is difficult to access programmatically. Workflows that assume a single team operating in isolation rather than a network of collaborators, let alone machine agents. None of these are catastrophic failures on their own, but together they create friction in places where the work is supposed to move quickly.
It’s not hard to understand how this happened. Many of these tools were built in a different era. The model was closer to licensed software than continuously evolving systems. You shipped a version, customers adapted to it, and updates came in discrete increments. Even as the industry moved toward SaaS, the underlying assumptions about how scientific work should be structured didn’t keep pace.
At the same time, everything around those tools changed. Teams became more distributed. Collaboration became more fluid. The browser became a capable runtime. Data volumes increased. And more recently, the expectation that you should be able to access and operate on your data programmatically - whether through APIs, MCPs, or something else entirely - became table stakes almost overnight.
Once you accept that shift, the idea of a “system of record” starts to look incomplete. Storing data is necessary, but insufficient. The system also needs to expose that data, allow it to be recomposed, and support workflows that extend beyond the boundaries of any single tool. It needs to behave less like a closed application and more like a platform that other processes can build on.
That realization changed how we thought about what we were building.
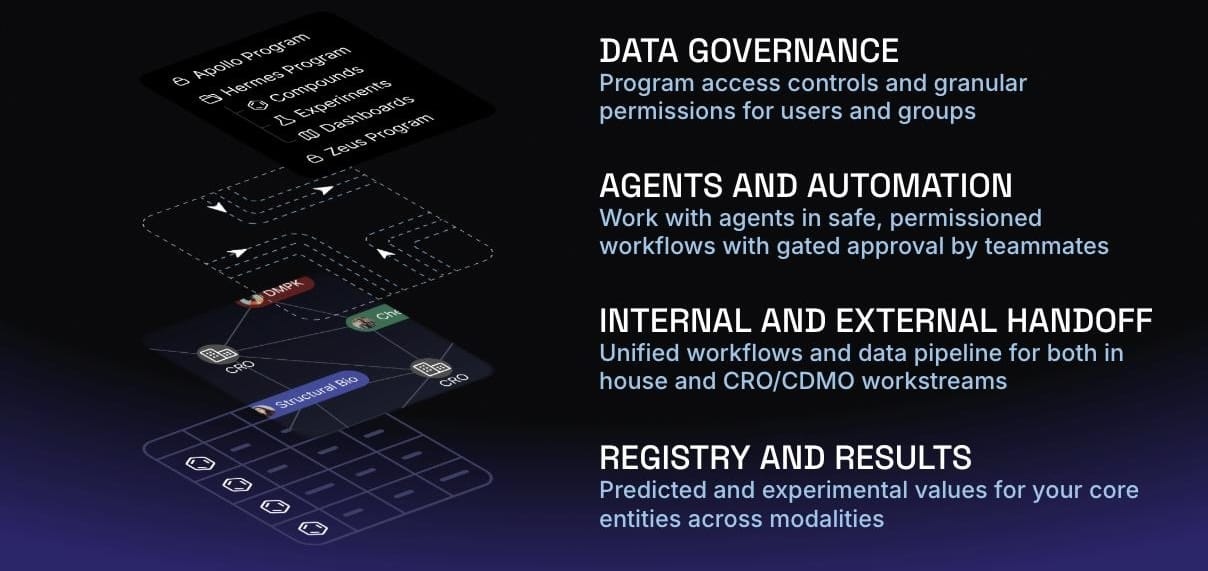
The integration-first approach still mattered, but it stopped being enough. If the surrounding systems couldn’t support the way teams actually wanted to work, then we had to fill in those gaps ourselves. What started as connecting decisions to underlying work gradually expanded into structuring experiments (virtual and real), tracking progress, managing collaboration, and exposing data in a way that made it usable outside the confines of the product.
From the outside, that can look like scope creep. From the inside, it felt more like following the shape of the problem.
The same dynamic is now playing out again with the introduction of language models. The expectation is no longer just that data is stored and accessible, but that it can be acted on. Queried, summarized, transformed, used to propose next steps. That only works if the underlying system is designed with access, permissions, and provenance in mind. Otherwise, the model has nothing reliable to operate on.
In that sense, the “platform of the future” isn’t defined by how many features it has; it’s defined by whether it treats data as something static or something that can be continuously used, recombined, and acted upon across workflows. It assumes collaboration includes not just people, but systems, services, and increasingly, agents. And it assumes that those collaborators need structured access to the same underlying context.
What we found, over time, was that the platform we assumed we were building on didn’t fully exist. The pieces were there, but they didn’t fit together in a way that supported how teams actually work. Once that became clear, the direction was hard to ignore. You either work around the gaps indefinitely, or you start filling them. Kaleidoscope exists in its current form because we chose the latter.